

Inhalt
Ich habe im April 2025 einen Gastbeitrag für die AFS Akademie zu Cost of Retrieval veröffentlicht. Seitdem habe ich in über 30 Audits gesehen, wie massiv Cost of Retrieval die Sichtbarkeit beeinflusst. Dieser Artikel geht deutlich tiefer – mit konkreten Zahlen aus echten Projekten und den Erkenntnissen, die ich seitdem gewonnen habe.
Cost of Retrieval: Das Konzept hinter dem Begriff
Cost of Retrieval stammt aus dem Information Retrieval – einem Forschungsfeld, das sich mit der gezielten Extraktion von Informationen aus großen Datenmengen beschäftigt. Übertragen auf SEO lautet die zentrale Frage: Lohnt sich der rechnerische Aufwand, Informationen aus einer Website zu extrahieren?
Auf der einen Seite steht die Rechenleistung, die Google aufwenden muss – Server-Anfragen, Rendering, Speicherung, mehrfache Snapshots. Auf der anderen Seite steht der Informationsgehalt der Seite. Überwiegt der Informationswert, crawlt und indexiert Google. Überwiegt der Aufwand, passiert nichts.
Das ist keine Theorie. Google speichert von jeder indexierten Seite mehrere Snapshots auf eigenen Servern. Bei einem Onlineshop mit 5.000 Produktseiten à 2 MB entstehen schnell 10 GB Speicherbedarf – nur für eine einzige Domain. Multipliziert mit Milliarden von Websites wird klar, warum Google extrem selektiv crawlt.
Warum Cost of Retrieval 2026 so relevant ist
Jeden Tag gehen Tausende neue Websites online – viele davon mit KI-generierten Inhalten, die in ähnlicher Form bereits existieren. Google filtert immer stärker. Die Schwelle, ab der sich das Crawlen lohnt, steigt kontinuierlich.
Modernes Retrieval läuft mehrstufig ab: lexikalische Kandidaten-Generierung, semantisches Retrieval, Reranking, Synthese. Cost of Retrieval entscheidet, ob eine Seite überhaupt in die erste Stufe gelangt. Wer hier rausfällt, existiert für Google und KI-Systeme nicht. Google bestätigt das indirekt in der offiziellen Crawl-Budget-Dokumentation: „Googlebot tries not to crawl too fast to avoid overloading the server.“ Google crawlt weniger, wenn dein Server langsam antwortet – so einfach ist das.
Koray Tugberk Gübür beschreibt Cost of Retrieval in seinem Semantic SEO Framework als einen der drei Grundpfeiler – neben Content Quality und Entity Understanding. Ganz ehrlich: Cost of Retrieval ist der Pfeiler, den die meisten SEOs übersehen, weil er nicht in Keyword-Rankings sichtbar wird. Cost of Retrieval wirkt im Verborgenen – und richtet dort den größten Schaden an.
Die 5 Faktoren, die den Cost of Retrieval bestimmen
1. Server-Antwortzeit (TTFB)
Time to First Byte (TTFB) misst die Zeitspanne zwischen der Anfrage des Crawlers und dem ersten empfangenen Byte der Server-Antwort. Google empfiehlt TTFB-Werte unter 200 Millisekunden. Realistisch sind 200–400 Millisekunden. Ab 600 Millisekunden steigt der Cost of Retrieval messbar.
Bei einem E-Commerce-Kunden lag die durchschnittliche Server-Reaktionszeit in der Google Search Console bei über 600 Millisekunden – obwohl Cloudflare vorgeschaltet war. Die Crawling-Statistiken zeigten: Der Server reagierte viermal langsamer als empfohlen. Bei einem anderen Kunden erreichten die Kategorieseiten 900 Millisekunden TTFB. Der Grund: 48 Produkte plus Topseller wurden bei jedem Seitenaufruf ungecacht aus der Datenbank geladen. Ohne Cache waren die Kategorieseiten vier- bis achtmal langsamer als mit Cache.
Warum ist das problematisch? Google crawlt nicht immer mit warmem Cache. Der Googlebot erfasst die langsame Version, wenn er eine Kategorieseite ohne Cache trifft – und bewertet den Cost of Retrieval entsprechend hoch.
Ich habe Martin Splitt – Developer Advocate bei Google – im Oktober 2025 auf Mastodon direkt gefragt, wie man den TTFB noch weiter runterbekommt. Mein Setup: schlankes WordPress auf OpenLiteSpeed, dedizierter Hetzner-Server, an allem gedreht, trotzdem maximal 300 Millisekunden in der GSC. Seine Antwort: „300ms is ja schon super. Bedenke, dass wir meistens aus den USA crawlen, also könnte ein CDN da helfen, aber ich würd bei so einer niedrigen response time jetzt nicht zu viel drüber nachdenken.“
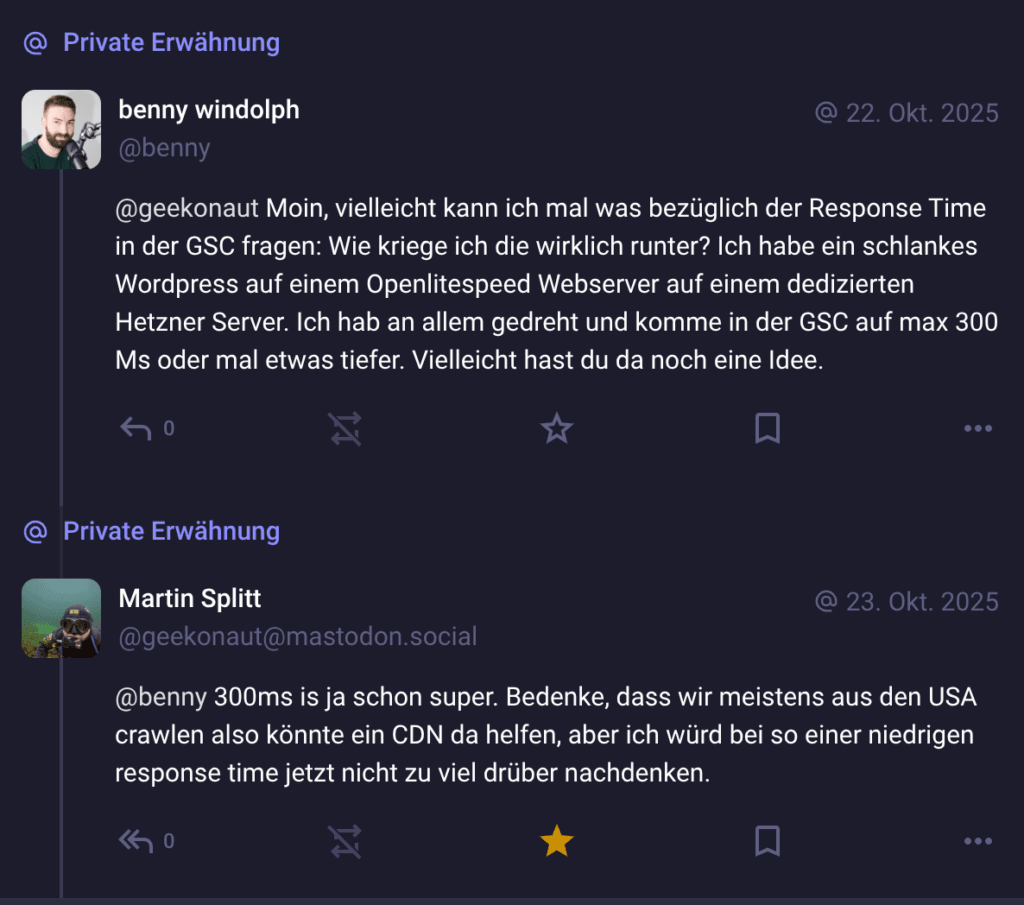
Das bestätigt letztlich: Unter 300 Millisekunden ist exzellent. Google crawlt aus den USA – die physische Distanz zum Server fließt deswegen direkt in den TTFB ein. Ein CDN wie Cloudflare kann hier helfen, aber ab 300 Millisekunden ist der Grenznutzen gering.
Empfehlung: TTFB unter 400 Millisekunden halten. Unter 300 Millisekunden ist laut Google exzellent. Wer über 600 Millisekunden liegt, verliert messbar Crawl-Frequenz. Die Crawling-Statistiken in der Google Search Console (unter Einstellungen) zeigen den exakten TTFB-Wert.
2. Seitengröße und HTML-Komplexität
Jedes zusätzliche Megabyte erhöht den Cost of Retrieval, weil Google mehr Speicher und Rechenleistung aufwenden muss. Produkt- und Kategorieseiten sollten maximal 1–2 Megabyte groß sein.
Bei einem Kunden lieferten die Bing Webmaster Tools den Hinweis „HTML zu lang“. Der Quelltext bestätigte das Problem: über 12.000 Zeilen HTML – 8.000 Zeilen mehr als bei vergleichbaren Wettbewerber-Websites. Bei solchen Dimensionen kann Google die Seite beim Crawlen nicht vollständig erfassen, weil irgendwann das Zeitlimit greift.
Große Hero-Slider und eingebettete Videos blähen Seiten auf bis zu 15 MB auf. Das nähert sich der von Google festgelegten Obergrenze für HTML-Seiten. Drei konkrete Maßnahmen: Slider entfernen, Videos extern einbetten, Bilder komprimieren.
3. Rendering-Aufwand und JavaScript-Abhängigkeit
Zwischen einem statischen Blog und einer JavaScript-lastigen Single Page Application liegt eine enorme Bandbreite im Cost of Retrieval. Google kann JavaScript rendern – aber das Rendering kostet Rechenzeit, und diese Rechenzeit fließt direkt in den Cost of Retrieval.
Bei einem Shopware-Kunden blockierte die robots.txt Teile des Widgets-Subdirectories. Die Folge: Die Startseite konnte beim Rendern nicht vollständig geladen werden. Google speicherte die Startseite ohne den eigentlichen Content – die wichtigste Seite der Domain, inhaltsleer im Index. Solche Probleme entdeckt man nur, wenn man den gerenderten Output in der Google Search Console prüft.
Ein weiteres Cost-of-Retrieval-Problem bei JavaScript: Content, der auf dem Handy erst nach Klick auf „Mehr erfahren“ nachgeladen wird. Google crawlt Mobile First. Das heißt: Google behandelt den Content als Hidden Content und ignoriert ihn möglicherweise komplett, wenn der Text hinter einem Overlay versteckt ist.
Pro-Tipp: Interne Verlinkung per JavaScript vermeiden. Crawler können JavaScript-Links im Zweifelsfall nicht interpretieren und folgen JavaScript-Links nicht. Klassische <a href>-Links sind die sichere Variante.
4. Crawl Budget und Seitenanzahl
Crawl Budget beschreibt die Anzahl der Seiten, die Google auf einer Domain in einem bestimmten Zeitraum crawlt. Je mehr Seiten existieren, desto stärker verteilt Google das Crawl Budget – und desto weniger Aufmerksamkeit erhält jede einzelne Seite. Ein hoher Cost of Retrieval auf vielen Seiten erschöpft das Crawl Budget schneller.
Bei einem Shopware-Kunden zeigte die Google Search Console ein Indexierungsverhältnis von 4:1. Etwa 2.800 URLs waren nicht indexiert, während nur rund 700 URLs im Index standen. Google verschwendete einen Großteil des Crawl Budgets für Seiten, die am Ende nicht indexiert wurden – 404-Fehler, 500er-Fehler, Duplikate.
Bei einem anderen Kunden haben wir die nicht-indexierten Seiten systematisch bereinigt: von 786 auf 633, dann weiter runter. Parallel stieg die Crawl-Frequenz für die relevanten Seiten. Je weniger Seiten Google regelmäßig crawlen muss, desto weniger Crawl Budget wird für irrelevante URLs verbraucht.
Faustregel: Jede Seite ohne echten Mehrwert verschwendet Crawl Budget. Konsequent löschen oder per noindex aus dem Index nehmen.
5. Technische Roadblocks, die das Crawling verhindern
Neben den Performance-Faktoren existieren technische Fehler, die den Cost of Retrieval unendlich hoch treiben – weil sie das Crawling komplett blockieren:
- 429 Too Many Requests: Bei einem Kunden trat dieser Statuscode auf, als Semrush einen Backlink-Check durchführte. Der Server war überlastet. Google deprioritisiert eine Seite nach einem 429-Fehler und kommt nicht einfach später zurück.
- Fehlerhaft konfigurierte robots.txt: Der Crawler erhält versehentlich keinen Zugriff auf indexierungsrelevante Inhalte.
- Falsche Robots-Meta-Tags: noindex oder nofollow an Stellen, wo keins sein sollte.
- Weiterleitungsschleifen: Der Crawler läuft ins Leere und bricht ab.
- Falsche Canonical-Tags: Google indexiert die falsche URL-Version – oder gar keine.
- 500er-Fehler: Interne Serverprobleme verhindern den Zugriff komplett.
Cost of Retrieval optimieren: Server, Datenbank, Seitenstruktur
Was kann man konkret tun? Cost of Retrieval lässt sich auf 3 Ebenen senken.
Server und Hosting optimieren
Shared Hosting reicht für Business-Websites und Webshops in der Regel nicht aus. Wenn eine Website auf dem geteilten Server langsam antwortet, bremst das den Cost of Retrieval aller Websites auf demselben Server. Ein eigener Server – physisch oder Cloud – bietet mehr Performance und ermöglicht gezielte Optimierungen.
3 konkrete Maßnahmen für niedrigeren Cost of Retrieval auf Server-Ebene:
- Schneller Webserver: OpenLiteSpeed statt Apache einsetzen. OpenLiteSpeed verarbeitet bis zu 60.000 Anfragen pro Sekunde.
- IPv6 und HTTP/3 aktivieren: Moderneres Routing, geringere Latenz, schnellere Antwortzeiten.
- DNS optimieren: Cloudflare bietet einen der schnellsten DNS-Dienste – kostenlos. Eine schnelle DNS-Auflösung verbessert direkt den TTFB.
Datenbank schlank halten
Bei CMS und Shopsystemen, die auf relationalen Datenbanken basieren: Datenbank regelmäßig optimieren. Eine aufgeblähte Datenbank ohne Indexierung und Caching verlängert die Zugriffszeiten bei jedem einzelnen Seitenaufruf – und erhöht damit den TTFB und den Cost of Retrieval.
Seitenstruktur statisch aufbauen
Seiten möglichst statisch aufbauen. Komplexe Effekte, die mit JavaScript statt CSS umgesetzt werden, erhöhen den Cost of Retrieval beim Rendering. Eine bewährte Faustregel: Wenn die Seite auch ohne JavaScript funktioniert, kann Google die Seite effizient crawlen.
Cost of Retrieval messen: Tools und Methoden
Google Search Console: Die Crawling-Statistiken unter Einstellungen zeigen die durchschnittliche Server-Reaktionszeit und die Crawl-Frequenz. Kommt der Googlebot nur selten vorbei, deutet das auf einen hohen Cost of Retrieval hin.
Bing Webmaster Tools: Oft unterschätzt. Die Bing Webmaster Tools liefern Hinweise wie „HTML zu lang“, die Google nicht explizit meldet.
site:-Befehl: site:domain.org in der Google-Suche zeigt alle indexierten Seiten. Stimmt die Anzahl der indexierten Seiten mit der erwarteten Seitenanzahl überein? Tauchen ungewollte Dateien wie PDFs im Index auf?
Crawling-Tools: Screaming Frog, Ahrefs oder Semrush für einen vollständigen Crawl. Screaming Frog crawlt bis zu 500 URLs kostenlos.
Quelltext-Check: Ein direkter Blick in den HTML-Code lohnt sich immer. Falsch gesetzte Robots-Meta-Tags oder fehlerhafte Canonical-Tags zeigen sich im Quelltext sofort.
Cost of Retrieval in der Praxis: Keywordkönig-Wettbewerb
Beim SEO-Wettbewerb von Agenturtipp 2025 zum Keyword „Keywordkönig“ war Cost of Retrieval einer der drei Hebel, mit denen wir Platz 3 bei Google und den ersten Platz beim KI-Wettbewerb von RankScale erreicht haben.
Cost of Retrieval war der erste Hebel: eine technisch schnelle, leicht abrufbare Website. Kein aufgeblähtes CMS, schlankes HTML, schneller Server, minimales JavaScript. Google konnte die Seite effizient crawlen und indexieren – in einer Wettbewerbssituation, in der Geschwindigkeit buchstäblich den Unterschied machte.
Die anderen beiden Hebel – Information Gain durch semantisch optimierten Content und Brand SEO – konnten nur wirken, weil die technische Basis stimmte. Cost of Retrieval ist die Voraussetzung für Sichtbarkeit, nicht das Sahnehäubchen.
Häufige Fragen zu Cost of Retrieval
Was genau ist Cost of Retrieval im SEO?
Cost of Retrieval ist das Verhältnis zwischen dem Aufwand, den Google für das Crawlen und Indexieren einer Seite aufwenden muss, und dem Informationsgehalt der Seite. Überwiegt der Aufwand den Nutzen, crawlt Google die Seite seltener oder ignoriert die Seite komplett.
Warum sind nicht alle meine Seiten bei Google indexiert?
Nicht alle Seiten einer Website werden indexiert, weil die Seiten entweder den qualitativen Ansprüchen von Google nicht genügen oder weil Google die Website nicht ordnungsgemäß crawlen kann. Häufige Ursachen sind 3: zu hoher TTFB, zu viele Seiten ohne Mehrwert und technische Fehler wie 404er oder falsche Canonical-Tags. Die Google Search Console zeigt unter „Seiten“ den genauen Indexierungsstatus jeder URL.
Welcher TTFB-Wert ist gut für SEO?
Google empfiehlt TTFB-Werte unter 200 Millisekunden. Realistisch und akzeptabel sind 200–400 Millisekunden. Ab 600 Millisekunden wird der Cost of Retrieval zum messbaren Problem für die Crawl-Frequenz. Werte über 900 Millisekunden, wie ich sie bei E-Commerce-Kunden gemessen habe, stuft Google als inakzeptabel ein.
Wie hängen Cost of Retrieval und Crawl Budget zusammen?
Cost of Retrieval bestimmt, wie effizient Google das Crawl Budget einer Domain nutzen kann. Hoher Cost of Retrieval bedeutet: Google verbraucht mehr Ressourcen pro Seite und crawlt weniger Seiten insgesamt. Niedriger Cost of Retrieval bedeutet: Google crawlt mehr Seiten in derselben Zeit – die relevanten Inhalte werden schneller und zuverlässiger indexiert.
Beeinflusst Cost of Retrieval die Sichtbarkeit in KI-Systemen?
Cost of Retrieval beeinflusst die Sichtbarkeit in KI-Systemen indirekt. KI-Systeme wie ChatGPT, Perplexity und Google AI Mode greifen auf Googles Index und eigene Crawling-Daten zurück. Wenn Google eine Seite nicht effizient crawlt und indexiert, fehlt die Seite in den Datenquellen der KI-Systeme – und kann folglich nicht zitiert werden. Beim Keywordkönig-Wettbewerb 2025 war genau dieser Zusammenhang zwischen Cost of Retrieval und KI-Sichtbarkeit der entscheidende Faktor für den Gewinn des KI-Wettbewerbs.
Quellen
- Windolph, Benny (2025): „Cost of Retrieval: Warum Google manche Seiten nicht crawlt oder indexiert“, AFS Akademie
- Gübür, Koray Tugberk: „Semantic SEO“, Holistic SEO Digital – Cost of Retrieval als Grundpfeiler
- Splitt, Martin (2025): Mastodon-Konversation zu TTFB und Googlebot-Crawling aus den USA, Google Developer Advocate
- Google: „Managing your crawl budget for large sites“, Google Search Central
- Google: „How Google Search works“, Google Search Central – Crawling, Indexing, Serving Pipeline
- Screaming Frog: „How to Find Expired Domains“ – Crawl-Analyse-Methodik