---
title: "Cost of Retrieval und Crawl Budget: Was Google das Crawlen wirklich kostet"
description: "Cost of Retrieval bestimmt, ob Google und KI-Crawler deine Seite abrufen oder ignorieren. TTFB, Rendering, Firewalls: konkrete Zahlen aus über 30 Audits."
url: https://hechtinsgefecht.de/cost-of-retrieval/
date_published: 2026-03-10
date_modified: 2026-07-08
---
# Cost of Retrieval und Crawl Budget: Was Google das Crawlen wirklich kostet
## Inhalt
1. [Cost of Retrieval: Das Konzept hinter dem Begriff](#cost-of-retrieval-das-konzept-hinter-dem-begriff)
2. [Warum Cost of Retrieval 2026 so relevant ist](#warum-cost-of-retrieval-2026-so-relevant-ist)
3. [Die 5 Faktoren, die den Cost of Retrieval bestimmen](#die-5-faktoren-die-den-cost-of-retrieval-bestimmen)
4. [Cost of Retrieval für KI-Crawler: GPTBot, ClaudeBot und Co.](#cost-of-retrieval-fur-ki-crawler-gptbot-claudebot-und-co)
5. [Cost of Retrieval optimieren: Server, Datenbank, Seitenstruktur](#cost-of-retrieval-optimieren-server-datenbank-seitenstruktur)
6. [Cost of Retrieval messen: Tools und Methoden](#cost-of-retrieval-messen-tools-und-methoden)
7. [Cost of Retrieval in der Praxis: Keywordkönig-Wettbewerb](#cost-of-retrieval-in-der-praxis-keywordkonig-wettbewerb)
8. [Die Grenze: Wenn niedriger Cost of Retrieval nicht reicht](#die-grenze-wenn-niedriger-cost-of-retrieval-nicht-reicht)
9. [Häufige Fragen zu Cost of Retrieval](#haufige-fragen-zu-cost-of-retrieval)
10. [Quellen](#quellen)
Im April 2025 habe ich für die AFS Akademie einen Gastbeitrag zu Cost of Retrieval veröffentlicht. Seitdem habe ich in über 30 Audits gesehen, wie massiv Cost of Retrieval und das verfügbare Crawl Budget die Sichtbarkeit beeinflussen. Hier gehe ich deutlich tiefer: mit konkreten Zahlen aus echten Projekten und den Erkenntnissen, die ich seitdem gewonnen habe. Und mittlerweile crawlt längst nicht mehr nur Google: KI-Crawler wie GPTBot stellen eigene Anforderungen an deine Website.
## Cost of Retrieval: Das Konzept hinter dem Begriff
Cost of Retrieval ist der Rechenaufwand, den Google für das Abrufen und Verarbeiten einer Seite investieren muss. Der Begriff kommt aus dem Information Retrieval, einem Forschungsfeld, das sich mit der gezielten Extraktion von Informationen aus großen Datenmengen beschäftigt. Googlebot ist Googles Web Crawler: ein automatisiertes Programm, das Webseiten systematisch abruft und deren Inhalte für den Suchindex aufbereitet. Für SEO lautet die zentrale Frage letztlich: Lohnt sich der rechnerische Aufwand, Informationen aus einer Website zu extrahieren?
Auf der einen Seite steht die Rechenleistung, die Google investieren muss: Server-Anfragen, Rendering, Speicherung, mehrfache Snapshots. Auf der anderen Seite steht der Informationsgehalt der Seite. Ist der Informationswert höher, crawlt und indexiert Google. Ist der Aufwand höher, passiert nichts.
Das ist keine Theorie. Google speichert von indexierten Seiten Snapshots auf eigenen Servern. Bei einem Onlineshop mit 5.000 Produktseiten à 2 MB kommen schnell 10 GB Speicherbedarf zusammen, nur für eine einzige Domain. Rechnet man das auf Milliarden von Websites hoch, wird ziemlich klar, warum Google extrem selektiv crawlt.
Kosten-Nutzen-Abwägung von Google: Was investiert wird vs. was eine Seite liefern muss
Kosten-Nutzen-Abwägung
Was Google investieren muss
Kosten
Server-Anfragen senden und verarbeiten
JavaScript rendern (Headless Chrome)
Mehrere Snapshots pro Seite speichern
5.000 Seiten × 2 MB = 10 GB pro Domain
VS
Was die Seite liefern muss
Nutzen
Einzigartiger, relevanter Content
Neuer Informationsgehalt (Information Gain)
Klarer Nutzen für Suchende
Saubere Technik, schnelle Auslieferung
Aufwand > Nutzen → Google ignoriert die Seite
Nutzen > Aufwand → Google crawlt und indexiert
Abb. 1 · HECHT INS GEFECHT
Abb. 1: Kosten-Nutzen-Abwägung, Rechenaufwand vs. Informationswert beim Crawlen
## Warum Cost of Retrieval 2026 so relevant ist
Jeden Tag gehen Tausende neue Websites online, viele davon mit KI-generierten Inhalten, die in ähnlicher Form schon existieren. Google filtert mittlerweile immer stärker. Die Schwelle, ab der sich das Crawlen für Google lohnt, steigt seit 2024 kontinuierlich.
Modernes Retrieval läuft mehrstufig ab: lexikalische Kandidaten-Generierung, semantisches Retrieval, Reranking, Synthese. Cost of Retrieval entscheidet, ob eine Seite überhaupt in die erste Stufe gelangt. Wer hier rausfällt, existiert für Google und [KI-Systeme](https://hechtinsgefecht.de/llm-sichtbarkeit/) nicht. Google bestätigt das indirekt in der offiziellen [Crawl-Budget-Dokumentation](https://developers.google.com/search/docs/crawling-indexing/large-site-managing-crawl-budget). Dort heißt es: „Googlebot tries not to crawl too fast to avoid overloading the server.“ Google crawlt weniger, wenn dein Server langsam antwortet. So einfach ist das.
Koray Tuğberk Gübür, Gründer von Holistic SEO Digital, beschreibt Cost of Retrieval in seinem [Semantic SEO Framework](https://www.holisticseo.digital/seo-research-study/semantic-search) als einen der drei Grundpfeiler. Die anderen beiden sind Content Quality und Entity Understanding. Cost of Retrieval ist der am häufigsten übersehene Pfeiler, weil er nicht in Keyword-Rankings sichtbar wird. Cost of Retrieval wirkt im Verborgenen und richtet dort den größten Schaden an.
Dazu kommt eine zweite Crawler-Flotte: GPTBot, der Trainings-Crawler von OpenAI, hat sein Abrufvolumen laut Cloudflare binnen eines Jahres um über 300 Prozent gesteigert (Daten bis Mitte 2025). Auch diese Crawler wägen Aufwand gegen Nutzen ab, nur nach härteren Regeln als Google. Was das konkret heißt, steht weiter unten im Kapitel zu den KI-Crawlern.
## Die 5 Faktoren, die den Cost of Retrieval bestimmen
Fünf Faktoren bestimmen, wie teuer eine Seite für Google im Abruf ist: Server-Antwortzeit (TTFB), Seitengröße, Rendering-Aufwand, Crawl Budget und technische Roadblocks. Die folgenden Abschnitte zeigen für jeden Faktor konkrete Messwerte aus Kundenprojekten.
Die fünf Faktoren des Cost of Retrieval
5 Faktoren des Cost of Retrieval
1
Server-Antwortzeit (TTFB)
Ziel: unter 400 ms. Ab 600 ms sinkt die
Crawl-Frequenz messbar.
2
Seitengröße und HTML-Komplexität
Maximal 1–2 MB. Aufgeblähtes HTML
kostet Rechenzeit pro Request.
3
Rendering-Aufwand (JavaScript)
JS-Rendering kostet extra.
Statisches HTML wird bevorzugt.
4
Crawl Budget und Seitenanzahl
Mehr Seiten = weniger Budget pro Seite.
Dünnen Content konsequent bereinigen.
5
Technische Roadblocks
429, robots.txt, noindex, Redirects,
Canonicals und 500er-Fehler.
Jeder Faktor erhöht den Aufwand für Google.
Abb. 2 · HECHT INS GEFECHT
*Abb. 2: Die 5 Faktoren des Cost of Retrieval*
### 1. Server-Antwortzeit (TTFB)
Time to First Byte (TTFB) misst die Zeitspanne zwischen der Anfrage des Crawlers und dem ersten empfangenen Byte der Server-Antwort. Google empfiehlt TTFB-Werte unter 200 Millisekunden. Realistisch sind 200 bis 400 Millisekunden. Ab 600 Millisekunden steigt der Cost of Retrieval messbar.
Bei einem E-Commerce-Kunden lag die durchschnittliche Server-Reaktionszeit in der Google Search Console bei über 600 Millisekunden, obwohl Cloudflare vorgeschaltet war. Die Crawling-Statistiken zeigten: Der Server reagierte viermal langsamer als empfohlen. Bei einem anderen Kunden erreichten die Kategorieseiten 900 Millisekunden TTFB. Der Grund: 48 Produkte plus Topseller wurden bei jedem Seitenaufruf ungecacht aus der Datenbank geladen. Ohne Cache waren die Kategorieseiten vier- bis achtmal langsamer als mit Cache.
Problematisch wird das, weil Google nicht immer mit warmem Cache crawlt. Der Googlebot erfasst die langsame Version, wenn er eine Kategorieseite ohne Cache trifft, und bewertet den Cost of Retrieval entsprechend hoch.
Ein Shopware-6-Fall aus dem Sommer 2026 zeigt, was ein Cache kostet, der am Crawler vorbeizielt. Der HTTP-Cache der Website war aktiv und funktionierte, nur eben nie für den Googlebot: Shopware liefert Cache-Treffer in dieser Konfiguration nur an Clients mit einem bestimmten Cookie aus. Der Googlebot sendet keine Cookies und traf deswegen bei jedem Abruf einen vollen PHP-Render.
Das Ergebnis in der GSC: durchschnittlich 1.070 Millisekunden Abrufzeit. Mit Cookie antwortete derselbe Server in 160 bis 290 Millisekunden.
Ich habe Martin Splitt, Developer Advocate bei Google, im Oktober 2025 auf Mastodon direkt gefragt, wie man den TTFB noch weiter runterbekommt. Mein Setup: schlankes WordPress auf OpenLiteSpeed, dedizierter Hetzner-Server, an allem gedreht, trotzdem maximal 300 Millisekunden in der Google Search Console (GSC). Seine Antwort: „300ms is ja schon super. Bedenke, dass wir meistens aus den USA crawlen, also könnte ein CDN da helfen, aber ich würd bei so einer niedrigen response time jetzt nicht zu viel drüber nachdenken.“
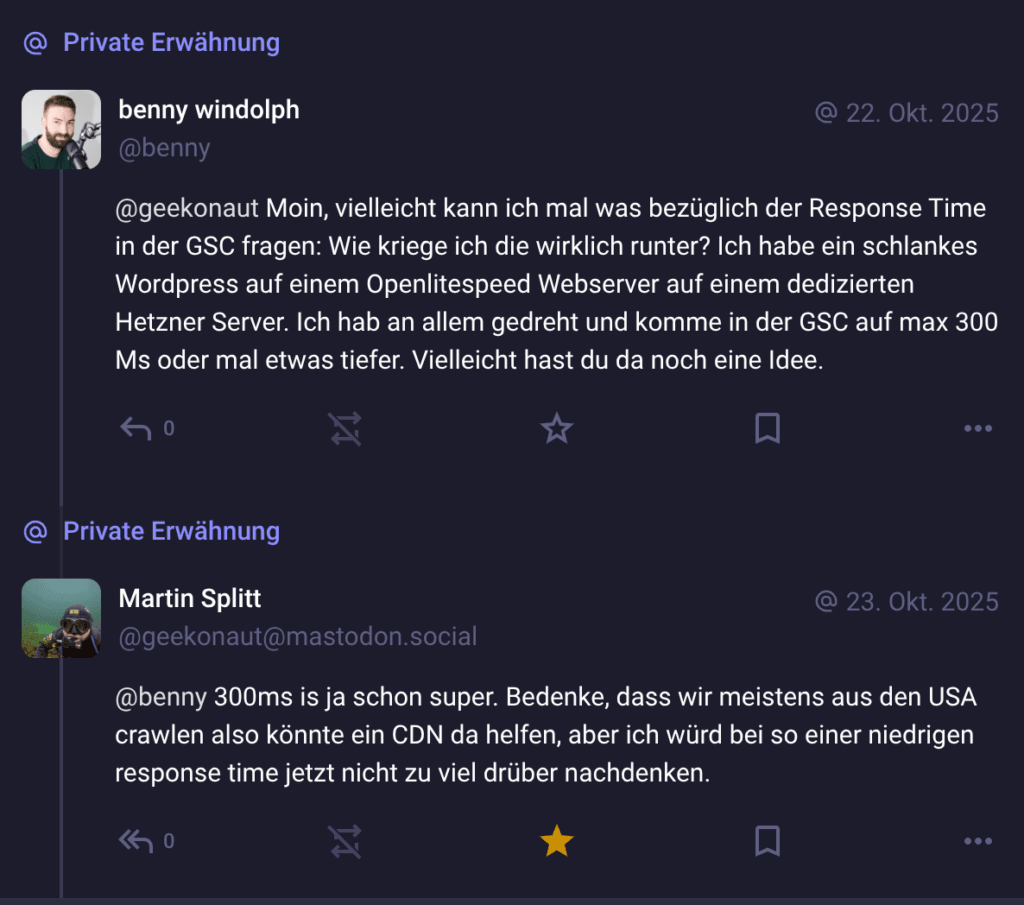
Das bestätigt letztlich: Unter 300 Millisekunden ist exzellent. Google crawlt überwiegend aus den USA. Die physische Distanz zum Server kann sich deswegen auf den TTFB auswirken. Ein CDN wie Cloudflare kann hier helfen, aber ab 300 Millisekunden ist der Grenznutzen gering. Der Shopware-Fall von oben zeigt, wie groß der Effekt werden kann: Lokal gemessen, also ohne den US-Umweg, aber ebenfalls ohne Cookie und damit am Cache vorbei, antwortete der Server in rund 356 Millisekunden. Die GSC meldete 1.070. Der Weg über den Atlantik hat den Wert verdreifacht.
Empfehlung: TTFB unter 400 Millisekunden halten. Unter 300 Millisekunden ist laut Google exzellent. Wer über 600 Millisekunden liegt, verliert messbar Crawl-Frequenz. Den exakten TTFB-Wert zeigen die Crawling-Statistiken in der Google Search Console unter Einstellungen.
TTFB-Skala: Vier Zonen zur Bewertung der Server-Antwortzeit
TTFB: Server-Antwortzeit bewerten
Exzellent
Google-Empfehlung. Ideale Antwortzeit.
< 200 ms
Gut
Akzeptabel für die meisten Websites.
200–400 ms
Kritisch
Cost of Retrieval steigt messbar.
400–600 ms
Problem
Crawl-Frequenz sinkt. Sofort handeln.
> 600 ms
„
300 ms ist ja schon super. Bedenke, dass wir
meistens aus den USA crawlen.
– Martin Splitt, Google Developer Advocate
Abb. 3 · HECHT INS GEFECHT
Abb. 3: TTFB-Skala, Server-Antwortzeiten von exzellent bis kritisch
### 2. Seitengröße und HTML-Komplexität
Google hat im März 2026 erstmals die konkreten Byte-Limits der Crawling-Infrastruktur offengelegt. Googlebot lädt bei einer HTML-Seite maximal die ersten 2 MB, inklusive HTTP Header. Bei PDF-Dateien liegt die Grenze bei 64 MB. Alles oberhalb der 2 MB rendert Google nicht, indexiert es nicht und, klar, für Google ist es schlicht nicht da.
Entscheidend ist, was bei einer Überschreitung passiert: Google weist die Seite nicht zurück, sondern kappt sie exakt bei 2 MB und verarbeitet dieses Fragment, als wäre es die komplette Datei. Liegen strukturierte Daten, das Canonical-Tag oder die Meta Description hinter der 2 MB Marke, fehlen diese Elemente für Google vollständig. Das passiert etwa, wenn davor Megabytes an Inline-CSS, Base64-Bildern oder ein aufgeblähtes Mega-Menü sitzen. Die Reihenfolge im HTML-Quelltext ist deswegen nicht bloß Best Practice, sondern letztlich existenziell. Title, canonical, meta description und structured data gehören so weit nach oben wie möglich.
Ein weiteres Detail aus dem Blogpost: Sub-Ressourcen wie JavaScript- und CSS-Dateien haben jeweils ein eigenes 2 MB Limit. Sie zählen nicht gegen die Größe der übergeordneten HTML-Seite. Ein fettes JS-Bundle mit 3 MB wird also ebenfalls bei 2 MB abgeschnitten, unabhängig davon, wie schlank die HTML-Seite selbst ist. Medien, Fonts und einige exotische Dateitypen werden vom Web Rendering Service gar nicht erst angefordert.
Bei einem Kunden lieferten die Bing Webmaster Tools den Hinweis „HTML zu lang“. Der Quelltext bestätigte den Hinweis: über 12.000 Zeilen HTML, 8.000 Zeilen mehr als bei vergleichbaren Wettbewerber-Websites. Bei solchen Dimensionen riskiert man, dass Google die Seite nicht vollständig erfasst, weil der Content jenseits des 2 MB Cutoffs liegt.
Große Hero-Slider und eingebettete Videos blähen Seiten auf bis zu 15 MB auf. Drei konkrete Maßnahmen: Slider entfernen, Videos extern einbetten, Bilder komprimieren. Und eine vierte: Kritische HTML-Elemente an den Anfang des Quelltexts verschieben: vor Menüs und vor Inline-Ressourcen.
### 3. Rendering-Aufwand und JavaScript-Abhängigkeit
Zwischen einem statischen Blog und einer JavaScript-lastigen Single Page Application liegt eine enorme Bandbreite im Cost of Retrieval. Google kann JavaScript rendern, aber das Rendering kostet Rechenzeit, und diese Rechenzeit fließt direkt in den Cost of Retrieval.
Bei einem Shopware-Kunden blockierte die robots.txt Teile des Widgets-Subdirectories. Die Folge: Die Startseite konnte beim Rendern nicht vollständig geladen werden. Google speicherte die Startseite ohne den eigentlichen Content: die wichtigste Seite der Domain, inhaltsleer im Index. Solche Probleme entdeckt man nur, wenn man den gerenderten Output in der Google Search Console prüft.
2026 habe ich bei einem großen Fashion-Onlineshop mit Headless-Frontend (das Frontend baut die Seiten per JavaScript aus einer Schnittstelle zusammen) gesehen, was clientseitiges Rendering wirklich kostet. Die Kategorieseiten lieferten serverseitig keine 30 Wörter aus. Erst nach der JavaScript-Ausführung standen rund 700 Wörter im DOM (dem fertig aufgebauten Seiteninhalt im Browser). Im statischen HTML fand sich statt des Produktgrids nur ein Lade-Spinner, und kein einziger Link auf Produktdetailseiten. Der komplette Crawl-Pfad in die Tiefe der Website hing damit an Googles zweitem Rendering-Schritt.
Die Folge stand in der Search Console: über 100.000 Seiten gecrawlt, aber nicht indexiert, überwiegend valide Produkte und Kategorien. Dass dieser zweite Schritt Zeit kostet, ist gemessen: In einer [Onely-Auswertung](https://www.onely.com/blog/google-needs-9x-more-time-to-crawl-js-than-html/) folgte der Googlebot einem per JavaScript erzeugten Link erst nach 52 Stunden, demselben Link im statischen HTML nach 25 Stunden.
Die Lösung ist übrigens selten ein komplettes Server-Side-Rendering. Der Shop hatte gute Gründe für JavaScript: Login-abhängige Preise, Live-Lagerbestand. Der Split macht den Unterschied: statische Inhalte wie Text, Produktliste und Links serverseitig ausliefern, nur Preis- und Bestandsdaten dynamisch nachladen.
Google hat außerdem bestätigt, dass der Web Rendering Service (WRS) komplett zustandslos arbeitet: Local Storage und Session-Daten werden zwischen Requests gelöscht. JavaScript, das auf gespeicherte Session-Daten angewiesen ist, um Content auszugeben, produziert im WRS leere Seiten. Auch hier gilt das 2 MB Limit: Der WRS kann nur den Code ausführen, den der Crawler tatsächlich abgerufen hat. Wird ein JavaScript-Bundle bei 2 MB abgeschnitten, fehlt dem WRS der Rest des Codes.
Ein weiteres Cost-of-Retrieval-Problem bei JavaScript: Content, der auf dem Handy erst nach Klick auf „Mehr erfahren“ nachgeladen wird. Google crawlt Mobile First. Das heißt: Google behandelt den Content als Hidden Content und ignoriert ihn möglicherweise komplett, wenn der Text hinter einem Overlay versteckt ist.
**Pro-Tipp:** Interne Verlinkung per JavaScript vermeiden. Crawler können JavaScript-Links im Zweifelsfall nicht zuverlässig interpretieren und folgen ihnen möglicherweise nicht. Klassische ``-Links sind die sichere Variante.
### 4. Crawl Budget und Seitenanzahl
Crawl Budget beschreibt die Anzahl der Seiten, die Google auf einer Domain in einem bestimmten Zeitraum crawlt. Je mehr Seiten existieren, desto stärker verteilt Google das Crawl Budget, und desto weniger Aufmerksamkeit erhält jede einzelne Seite. Ein hoher Cost of Retrieval auf vielen Seiten erschöpft das Crawl Budget schneller.
Bei einem Shopware-Kunden zeigte die Google Search Console ein Indexierungsverhältnis von 4:1. Etwa 2.800 URLs waren nicht indexiert, während nur rund 700 URLs im Index standen. Google verschwendete einen Großteil des Crawl Budgets für Seiten, die am Ende nicht indexiert wurden: 404-Fehler, 500er-Fehler, Duplikate.
Crawl-Budget-Verschwendung: Vier von fünf gecrawlten URLs landen nicht im Index
Crawl-Budget-Verschwendung
Indexierungsverhältnis eines E-Commerce-Kunden (Shopware)
Nicht indexiert
2.800
Indexiert
700
4 : 1
Vier von fünf gecrawlten URLs landen nicht im Index.
Ursachen der Verschwendung
404-Fehler und 500er-Fehler auf der Domain
Duplikate und Seiten ohne eigenen Mehrwert
Jede nicht-indexierte URL kostet Budget ohne Gegenwert.
Abb. 4 · HECHT INS GEFECHT
*Abb. 4: Crawl-Budget-Verschwendung, Indexierungsverhältnis 4:1*
Derselbe Fashion-Onlineshop aus dem Rendering-Abschnitt zeigt, wie das Muster nach oben skaliert: Im GSC-Domain-Property lag das Verhältnis bei rund 5:1, allein über 340.000 URLs antworteten mit 404. Dazu kamen mehr als ein Dutzend Länder-Shops mit nahezu identischem Sortiment, deren Sitemaps zusammen ein Vielfaches des eigentlichen Sortiments an URLs meldeten. Ohne serverseitiges hreflang (das Signal, welche Sprachversion für welches Land gedacht ist) crawlt Google lauter fast deckungsgleiche Seitenbäume und muss raten.
Noch drastischer war ein internationales Buchungsportal. Dort hängte der Login-Link an jede URL einen Login-Parameter an, auch an URLs, die den Parameter bereits trugen. Jede gecrawlte Variante verlinkte so auf eine noch längere Variante, eine klassische Spider-Trap (eine Linkstruktur, die Crawler in endlose URL-Varianten schickt).
Ein einzelner KI-Trainings-Crawler produzierte dort 94.000 Abrufe auf fast 93.000 einzigartigen URLs, bei nur einigen hundert echten Seiten. 99,3 Prozent des Crawls waren Duplikate. Das Canonical-Tag zeigte korrekt auf die saubere URL und hat den Index gerettet, das Crawl Budget nicht. Die GSC-Crawling-Statistiken desselben Portals zeigen zudem, wie viel Budget in Fehlern verbrennt: Nur 47 Prozent der Googlebot-Anfragen endeten mit Status 200. 19 Prozent liefen in 404-Fehler, 17 Prozent in Weiterleitungen. Dabei stand der Hoststatus auf Grün, der Server hätte mehr verkraftet. Google hätte also mehr crawlen können. Google wollte nur nicht.
Bei einem anderen Kunden haben wir die nicht-indexierten Seiten systematisch bereinigt: von 786 auf 633, dann weiter runter. Parallel stieg die Crawl-Frequenz für die relevanten Seiten. Je weniger Seiten Google regelmäßig crawlen muss, desto weniger Crawl Budget wird für irrelevante URLs verbraucht.
Wie hart diese Regel bei fehlender Autorität greift, habe ich im SEO-Contest 2026 erlebt: Eine Methoden-Unterseite mit stark überlappendem Content zur Homepage-Sektion blieb auf der brandneuen Domain trotz ultraschlanker Technik dauerhaft bei „gecrawlt, nicht indexiert“. Nach 6 Tagen habe ich sie eingestampft, per 301 auf die Startseite konsolidiert und die Sitemap von 4 auf 3 URLs reduziert, damit war das Problem gelöst. Niedriger Cost of Retrieval allein reicht nicht, wenn der Information Gain fehlt. Der Beitrag zur [Google Sandbox](https://hechtinsgefecht.de/google-sandbox/) erzählt den kompletten Contest-Fall.
**Faustregel:** Jede Seite ohne echten Mehrwert verschwendet Crawl Budget. Konsequent löschen oder per noindex aus dem Index nehmen. Besonders nach einem [Website-Relaunch](https://hechtinsgefecht.de/website-relaunch-seo/) häufen sich 404-Fehler und URL-Duplikate, die das Crawl Budget belasten. Das solltest du direkt im Audit-Prozess mitbereinigen.
### 5. Technische Roadblocks, die das Crawling verhindern
Neben den Performance-Faktoren existieren technische Fehler, die den Cost of Retrieval unendlich hoch treiben, weil sie das Crawling komplett blockieren:
- **429 Too Many Requests:** Bei einem Kunden trat dieser Statuscode auf, als Semrush einen Backlink-Check durchführte. Der Server war überlastet. Google deprioritisiert eine Seite nach einem 429-Fehler und kommt nicht einfach später zurück.
- **Fehlerhaft konfigurierte robots.txt:** Der Crawler erhält versehentlich keinen Zugriff auf indexierungsrelevante Inhalte.
- **Falsche Robots-Meta-Tags:** noindex oder nofollow an Stellen, wo keins sein sollte.
- **Weiterleitungsschleifen:** Der Crawler läuft ins Leere und bricht ab.
- **Falsche Canonical-Tags:** Google indexiert die falsche URL-Version, oder gar keine.
- **500er-Fehler:** Interne Serverprobleme verhindern den Zugriff komplett.
- **robots.txt-Wildcards, die ins Leere greifen:** Ein Muster wie Disallow: /\*?parameter\* blockiert nur URLs, bei denen der Parameter direkt hinter dem Fragezeichen steht. Steht er mit &-Verkettung weiter hinten in der URL, greift die Regel nicht. Beim erwähnten Buchungsportal crawlte selbst der regelkonforme Bingbot über 2.800 solcher URLs an der aktiven robots.txt vorbei. Der Fix: zusätzliche Disallow-Regeln für die &-Varianten.
- **Relative Pfade ohne führenden Slash:** Site-weite Links wie images/logo.png statt /images/logo.png werden unter Sprach- oder Kampagnenpfaden immer neu aufgelöst und erzeugen 404-Wellen. Bei einem Kunden produzierte ein einziges relativ verlinktes Theme-Bild 175 Fehlerabrufe unter 50 Pfadvarianten, 3,6 Prozent des gesamten Googlebot-Traffics.
- **Firewalls und Bot-Protection:** Web Application Firewalls und Bot-Schutz am CDN blocken Crawler, ohne dass die robots.txt davon etwas weiß. Der Statuscode-Check sieht sauber aus, solange man ihn nicht mit der richtigen Bot-Kennung fährt. Mehr dazu im nächsten Kapitel.
## Cost of Retrieval für KI-Crawler: GPTBot, ClaudeBot und Co.
Bis hierhin ging es um Google. Doch neben dem Googlebot crawlt heute eine ganze Reihe weiterer Bots das Web: GPTBot und OAI-SearchBot für OpenAI, ClaudeBot für Anthropic, PerplexityBot, dazu die Trainings-Crawler von Meta und anderen. Für alle gilt dasselbe Kosten-Nutzen-Prinzip, nur ohne Googles Geduld: kein Rendering, kein zweiter Versuch, kein Nachsehen bei langsamen Servern.
KI-Sichtbarkeit entsteht dabei auf drei Abruf-Ebenen. [Cloudflare Radar](https://radar.cloudflare.com/ai-insights) weist den KI-Bot-Traffic laufend nach Zweck aus: rund 80 Prozent der Abrufe dienen dem Modell-Training, 18 Prozent füttern Suchindizes, nur 2 Prozent sind Live-Abrufe während einer konkreten Nutzerfrage. Jede Ebene nutzt eigene Crawler mit eigenen Hürden. Und die Suchindizes dahinter sind selten Google: ChatGPT stützt sich auf Bing und einen eigenen Index, Claude auf Brave.
### KI-Crawler rendern kein JavaScript
Der wichtigste Unterschied zu Google: Keiner der großen KI-Crawler von OpenAI, Anthropic oder Perplexity führt JavaScript aus. Vercel und MERJ haben den KI-Crawler-Traffic im Vercel-Netzwerk ausgewertet, fast eine Milliarde Abrufe pro Monat. GPTBot, ClaudeBot und PerplexityBot laden JavaScript-Dateien zwar herunter, führen sie aber nicht aus. Was erst nach dem Rendering im DOM steht, existiert für KI-Systeme nicht.
Der Fashion-Onlineshop von oben, mit weniger als 30 Wörtern im statischen HTML, ist für Google deswegen ein Rendering-Kostenproblem. Für ChatGPT und Perplexity ist er schlicht eine leere Seite.
### Der Live-Abruf kennt keinen zweiten Versuch
Auf der dritten Ebene, dem Live-Abruf, wird aus dem TTFB-Faktor eine harte Schwelle. Serverlogs zeigen, dass der ChatGPT-Fetcher Abrufe schon ab etwa 500 bis 800 Millisekunden Antwortzeit abbricht, im nginx-Log sichtbar als Status 499. Der Googlebot kommt bei langsamer Antwort später wieder. Der Live-Abruf hat diese Geduld nicht: Die KI-Antwort wird dann ohne deine Website geschrieben.
Wie kaputt diese Abruf-Kette im Extremfall sein kann, habe ich beim [ChatGPT-Crawler-Bug](https://hechtinsgefecht.de/chatgpt-crawler-bug/) dokumentiert: Ein HTTP/2-Protokollfehler machte ganze Server für OpenAI unsichtbar, sämtliche 634 Abrufe unserer eigenen Domain liefen in 404-Fehler. Der Cost of Retrieval war damit faktisch unendlich, und niemand hat es gemerkt.
### Die Firewall als unsichtbarer Roadblock
Den Extremfall auf der Gegenseite habe ich 2026 bei demselben Fashion-Onlineshop analysiert. Dessen Web Application Firewall (eine Schutzschicht vor dem Webserver, die Anfragen filtert) beantwortete die Anfragen sämtlicher KI-Crawler mit dem Statuscode 403, obwohl die robots.txt kein einziges Disallow enthielt. Wer nur die Crawl-Steuerung prüft, findet nichts. Der Block sitzt eine Ebene tiefer und filtert zweistufig: bekannte Bot-Kennungen direkt an der Firewall, und wer wie ein Browser aussieht, aber kein JavaScript ausführt, bekommt eine JavaScript-Challenge statt der Seite.
Datieren ließ sich die Sperre ohne jeden Zugriff auf Server-Logs. Die Wayback Machine hatte den Shop 2025 noch fast durchgehend erfasst, seit dem Frühjahr 2026 kommt nur noch 403 zurück. Der Common Crawl (das öffentliche Webarchiv, aus dem viele KI-Trainingsdaten stammen) lieferte ab demselben Zeitraum kein einziges Dokument der Domain mehr. Zwei unabhängige öffentliche Archive datieren den Block auf dasselbe Zeitfenster.
Messbar ist auch das Ergebnis: Die technisch saubere, serverseitig gerenderte Corporate-Website des Unternehmens wurde doppelt so oft als Quelle in KI-Antworten zitiert wie der eigentliche Shop. Dabei war die Sperre eine nachvollziehbare Entscheidung, sie kam nach echter Bot-Überlastung. Die sauberere Lösung: gewünschte KI-Crawler gezielt über User-Agent plus die offiziellen IP-Bereiche der Anbieter durchlassen, statt pauschal alles zu blocken.
### robots.txt und llms.txt steuern weniger, als du denkst
Die robots.txt wirkt bei KI-Systemen nur einseitig. Die regelkonformen Index- und Trainings-Crawler wie GPTBot respektieren sie. Ausgerechnet die Live-Fetcher tun es teils ganz offiziell nicht: OpenAI hat den ChatGPT-User Ende 2025 aus der eigenen robots.txt-Compliance-Liste gestrichen, Metas Fetcher darf sie laut eigener Dokumentation umgehen. Und beim Buchungsportal von oben crawlte ein KI-Trainings-Crawler über 84.000 per Wildcard-Disallow gesperrte URLs einfach trotzdem. Wer Crawl Budget gegen KI-Bots verteidigen muss, braucht deswegen Rate-Limits am Server oder an der Edge (den CDN-Servern vor dem eigenen Server).
Und die llms.txt? Die Idee dahinter: eine kuratierte Inhaltsliste für KI-Systeme im Root der Website. Ehrlicherweise ist die Datei Stand heute wirkungslos. Kein großer Anbieter liest sie produktiv aus, Google hat sich explizit dagegen ausgesprochen, und in Serverlogs taucht sie praktisch nicht auf. Schaden richtet sie keinen an, einen messbaren Effekt hat sie aber auch nicht.
## Cost of Retrieval optimieren: Server, Datenbank, Seitenstruktur
Cost of Retrieval lässt sich auf 3 Ebenen senken: am Server, an der Datenbank und an der Seitenstruktur. Die größten Gewinne liegen erfahrungsgemäß beim Hosting, denn dort entsteht der TTFB.
Drei Ebenen der Optimierung: Server, Datenbank, Seitenstruktur
3 Ebenen der Optimierung
1
Server und Hosting
OpenLiteSpeed statt Apache einsetzen
IPv6 und HTTP/3 aktivieren
DNS optimieren (Cloudflare)
2
Datenbank
Revisionen, Transients und Spam bereinigen
Log-Tabellen regelmäßig prüfen
Indexierung und Caching sicherstellen
3
Seitenstruktur
Statisches HTML statt JavaScript-Rendering
Kein Lazy-Load-Text hinter Overlays
Interne Links als klassische
Jede Ebene senkt den Cost of Retrieval messbar.
Abb. 5 · HECHT INS GEFECHT
*Abb. 5: 3 Ebenen der Cost-of-Retrieval-Optimierung*
### Server und Hosting optimieren
Shared Hosting reicht für Business-Websites und Webshops in der Regel nicht aus. Wenn eine Website auf dem geteilten Server langsam antwortet, bremst das den Cost of Retrieval aller Websites auf demselben Server. Ein eigener Server (physisch oder Cloud) bietet mehr Performance und ermöglicht gezielte Optimierungen.
3 konkrete Maßnahmen für niedrigeren Cost of Retrieval auf Server-Ebene:
- **Schneller Webserver:** OpenLiteSpeed statt Apache einsetzen. OpenLiteSpeed verarbeitet bis zu 60.000 Anfragen pro Sekunde.
- **IPv6 und HTTP/3 aktivieren:** Moderneres Routing, geringere Latenz, schnellere Antwortzeiten.
- **DNS optimieren:** Cloudflare bietet einen der schnellsten DNS-Dienste, kostenlos. Eine schnelle DNS-Auflösung verbessert direkt den TTFB.
### Datenbank schlank halten
Bei CMS und Shopsystemen, die auf relationalen Datenbanken basieren: Datenbank regelmäßig optimieren. Eine aufgeblähte Datenbank ohne Indexierung und Caching verlängert die Zugriffszeiten bei jedem einzelnen Seitenaufruf und erhöht damit den TTFB und den Cost of Retrieval. Bei WordPress erledigen Plugins wie WP-Optimize die Bereinigung automatisiert.
### Seitenstruktur statisch aufbauen
Seiten am besten so statisch wie möglich bauen. Komplexe Effekte, die per JavaScript statt per CSS laufen, treiben den Cost of Retrieval beim Rendering hoch. Die Faustregel ist klar: Wenn die Seite auch ohne JavaScript funktioniert, kann Google sie effizient crawlen.
## Cost of Retrieval messen: Tools und Methoden
Fünf kostenlose Wege zeigen den Cost of Retrieval: Die Google Search Console, die Bing Webmaster Tools, der site:-Befehl, Crawling-Tools und der Quelltext-Check.
Google Search Console: Unter Einstellungen zeigen die Crawling-Statistiken die durchschnittliche Server-Reaktionszeit und die Crawl-Frequenz. Schaut der Googlebot nur selten vorbei, spricht das eher für einen hohen Cost of Retrieval.
Vorsicht übrigens mit Server-Logs hinter einem CDN: Dienste wie Cloudflare beantworten einen Großteil der Googlebot-Anfragen direkt an der Edge, das eigene Server-Log sieht diese Abrufe nie. Beim Buchungsportal von oben zählte das Server-Log rund 470 Googlebot-Abrufe pro Tag, die GSC-Crawling-Statistiken meldeten 4.700. Hinter einem CDN taugt fürs Googlebot-Volumen nur die GSC. Und wer Logs auswertet, sollte die IP-Adressen verifizieren: Bei einem Shopware-Kunden bestanden 27 Prozent aller Anfragen mit Googlebot-Kennung den IP-Check nicht, dahinter steckten SEO-Tools und Spoofer.
Bing Webmaster Tools: Wird oft unterschätzt. Die Bing Webmaster Tools geben Hinweise wie „HTML zu lang“ aus, die Google nicht explizit meldet.
site:-Befehl: site:domain.org in der Google-Suche listet alle indexierten Seiten. Passt die Zahl der indexierten Seiten zur erwarteten Seitenanzahl? Tauchen ungewollte Dateien wie PDFs im Index auf?
Crawling-Tools: Screaming Frog, Ahrefs oder Semrush für einen vollständigen Crawl. Screaming Frog crawlt kostenlos bis zu 500 URLs. Wie du URLs danach gezielt zur Indexierung in Suchmaschinen und LLMs einreichst, zeigt der Artikel zur [Indexierung und LLM-Sichtbarkeit](https://hechtinsgefecht.de/indexierung-llm-sichtbarkeit/).
Quelltext-Check: Ein direkter Blick in den HTML-Code lohnt sich ehrlicherweise immer. Falsch gesetzte Robots-Meta-Tags oder fehlerhafte Canonical-Tags sieht man im Quelltext sofort.
## Cost of Retrieval in der Praxis: Keywordkönig-Wettbewerb
Beim SEO-Wettbewerb von Agenturtipp 2025 zum Keyword „Keywordkönig“ war Cost of Retrieval einer der drei Hebel. Mit ihnen haben wir Platz 3 bei Google und den ersten Platz beim KI-Wettbewerb von RankScale erreicht.
Cost of Retrieval war der erste Hebel: eine technisch schnelle, leicht abrufbare Website. Kein aufgeblähtes CMS, schlankes HTML, schneller Server, minimales JavaScript. Google konnte die Seite effizient crawlen und indexieren. Im Wettbewerb hat Geschwindigkeit buchstäblich den Unterschied gemacht.
Information Gain bezeichnet den messbaren Mehrwert, den ein Text gegenüber bereits indexierten Inhalten zum selben Thema liefert. Je höher der Information Gain, desto geringer der Cost of Retrieval für Google. Die anderen beiden Hebel, Information Gain durch [semantisch optimierten Content](https://hechtinsgefecht.de/semantisches-seo/) und [Brand SEO](https://hechtinsgefecht.de/brand-seo/), konnten nur wirken, weil die technische Basis stimmte. Cost of Retrieval ist die Voraussetzung für Sichtbarkeit, nicht das Sahnehäubchen.
Wer wissen will, wie hoch der Cost of Retrieval der eigenen Domain tatsächlich ist: Im [SEO-Audit](https://hechtinsgefecht.de/seo-audit/) analysieren wir das systematisch. Du bekommst konkrete Zahlen aus der Google Search Console, die Crawling-Statistiken und einen priorisierten Maßnahmenplan.
## Die Grenze: Wenn niedriger Cost of Retrieval nicht reicht
So zentral der Faktor ist, eine ehrliche Einordnung gehört dazu: Niedriger Cost of Retrieval ist die Eintrittskarte, kein Ranking-Garant. Das deutlichste Beispiel aus meiner Praxis ist ein Blog mit über 1.000 veröffentlichten Beiträgen. Der Googlebot kam regelmäßig bis täglich vorbei, die Technik war unauffällig. Trotzdem ergab eine Stichprobe über 25 gleichverteilte URLs: kein einziger Beitrag im Index, fast alle gecrawlt, aber nicht indexiert. Google hat die Seiten abgerufen, bewertet und wieder draußen gelassen.
Das ist beweisbar kein Crawling-Problem, das ist ein Werturteil. Die Methoden-Unterseite aus dem SEO-Contest 2026 weiter oben erzählt dieselbe Geschichte von der anderen Seite: ultraschlanke Technik, minimaler Cost of Retrieval, trotzdem dauerhaft nicht indexiert, weil der Inhalt mit der Startseite überlappte. Zwei Fälle mit demselben Muster. Wenn Seiten trotz regelmäßigem Crawling nicht in den Index kommen, fehlt der Information Gain: Die Seiten liefern nichts, was der Index nicht längst hat.
Deswegen gehört zu jeder Cost-of-Retrieval-Optimierung die unbequeme Frage, ob all diese Seiten existieren müssen. Bei dem Blog wäre der wirksamste Hebel die Konsolidierung: aus über 1.000 Beiträgen deutlich weniger, dafür dichte Seiten machen. Das senkt den Crawl-Aufwand und hebt den Informationswert, also beide Seiten der Gleichung gleichzeitig. Technik-Fixes allein lösen „gecrawlt, aber nicht indexiert“ nicht.
## Häufige Fragen zu Cost of Retrieval
### Was genau ist Cost of Retrieval im SEO?
Cost of Retrieval ist das Verhältnis zwischen dem Aufwand, den Google für das Crawlen und Indexieren einer Seite aufwenden muss, und dem Informationsgehalt der Seite. Überwiegt der Aufwand den Nutzen, crawlt Google die Seite seltener oder ignoriert die Seite komplett.
### Warum sind nicht alle meine Seiten bei Google indexiert?
Nicht alle Seiten einer Website werden indexiert. Entweder genügen die Seiten den qualitativen Ansprüchen von Google nicht, oder Google kann die Website nicht ordnungsgemäß crawlen. Drei Ursachen dominieren: zu hoher TTFB, zu viele Seiten ohne Mehrwert und technische Fehler wie 404er oder falsche Canonical-Tags. Die Google Search Console zeigt unter „Seiten“ den genauen Indexierungsstatus jeder URL.
### Welcher TTFB-Wert ist gut für SEO?
Google empfiehlt TTFB-Werte unter 200 Millisekunden. Realistisch und akzeptabel sind 200 bis 400 Millisekunden. Ab 600 Millisekunden wird der Cost of Retrieval zum messbaren Problem für die Crawl-Frequenz. Werte über 900 Millisekunden, wie ich sie bei E-Commerce-Kunden gemessen habe, stuft Google als inakzeptabel ein.
### Wie hängen Cost of Retrieval und Crawl Budget zusammen?
Cost of Retrieval bestimmt, wie effizient Google das Crawl Budget einer Domain nutzen kann. Hoher Cost of Retrieval bedeutet: Google verbraucht mehr Ressourcen pro Seite und crawlt weniger Seiten insgesamt. Niedriger Cost of Retrieval bedeutet: Google crawlt mehr Seiten in derselben Zeit. Die relevanten Inhalte werden schneller und zuverlässiger indexiert.
### Beeinflusst Cost of Retrieval die Sichtbarkeit in KI-Systemen?
Cost of Retrieval beeinflusst die Sichtbarkeit in KI-Systemen direkt. KI-Systeme beziehen Inhalte über drei Wege: Trainingsdaten, eigene Suchindizes (ChatGPT nutzt unter anderem Bing, Claude nutzt Brave) und Live-Abrufe während einer Antwort. Auf allen drei Ebenen arbeiten eigene Crawler, die kein JavaScript ausführen; der Live-Abruf bricht bei langsamen Antworten zudem schneller ab als der Googlebot. Eine Seite mit hohem Cost of Retrieval fehlt deswegen zuerst in den KI-Quellen und kann nicht zitiert werden.
### Warum crawlt Google meine Website nicht?
Wenn Google eine Website kaum oder gar nicht crawlt, dominieren drei Ursachen: technische Blockaden wie robots.txt-Fehler, Firewall-Sperren oder Serverfehler, ein zu hoher Cost of Retrieval durch langsame Antwortzeiten, oder fehlender Crawl-Bedarf, weil Google keinen neuen Informationswert erwartet. Die Crawling-Statistiken in der Google Search Console zeigen, welcher Fall vorliegt: Hoststatus und Antwortzeit decken Technik und Performance ab, die Crawl-Frequenz zeigt den Bedarf.
### Rendern KI-Crawler wie GPTBot JavaScript?
Nein. GPTBot, ClaudeBot und PerplexityBot laden JavaScript-Dateien zwar herunter, führen sie aber nicht aus. Inhalte, die erst clientseitig ins DOM gerendert werden, bleiben für KI-Systeme unsichtbar. Zuverlässig rendern nur klassische Suchmaschinen-Crawler wie der Googlebot, allerdings zeitverzögert und mit eigenem Rechenaufwand.
## Quellen
- Illyes, Gary (2026): [„Inside Googlebot: demystifying crawling, fetching, and the bytes we process“](https://developers.google.com/search/blog/2026/03/crawler-blog-post), Google Search Central Blog. Offizielle Byte-Limits: 2 MB HTML, 64 MB PDF, WRS-Statelessness, Partial Fetching
- Windolph, Benny (2025): [„Cost of Retrieval: Warum Google manche Seiten nicht crawlt oder indexiert“](https://www.afs-akademie.org/magazin/cost-of-retrieval/), AFS Akademie
- Gübür, Koray Tugberk: [„Semantic SEO“](https://www.holisticseo.digital/seo-research-study/semantic-search), Holistic SEO Digital. Cost of Retrieval als Grundpfeiler
- Splitt, Martin (2025): Mastodon-Konversation zu TTFB und Googlebot-Crawling aus den USA, Google Developer Advocate
- Google: [„Managing your crawl budget for large sites“](https://developers.google.com/search/docs/crawling-indexing/large-site-managing-crawl-budget), Google Search Central
- Google: [„How Google Search works“](https://developers.google.com/search/docs/fundamentals/how-search-works), Google Search Central. Crawling, Indexing, Serving Pipeline
- Screaming Frog: [„SEO Spider“](https://www.screamingfrog.co.uk/seo-spider/). Crawl-Analyse-Methodik
- Vercel und MERJ (2024): [„The Rise of the AI Crawler“](https://vercel.com/blog/the-rise-of-the-ai-crawler), Vercel. Auswertung von knapp einer Milliarde KI-Crawler-Abrufen pro Monat: KI-Crawler führen kein JavaScript aus
- Cloudflare (2025): [„From Googlebot to GPTBot: Who’s Crawling Your Site“](https://blog.cloudflare.com/from-googlebot-to-gptbot-whos-crawling-your-site-in-2025/), Cloudflare. Wachstum und Marktanteile der KI-Crawler; laufende Zweck-Aufteilung unter Cloudflare Radar AI Insights